Mamba核心作者新作:取代DeepSeek在用的注意力机制,专为推理打造
曾撼动Transformer统治地位的Mamba作者之一Tri Dao,刚刚带来新作——
提出两种专为推理“量身定制”的注意力机制。
在保持模型性能不变的情况下,将解码速度和吞吐量最高提升2倍,大大优化了模型的长上下文推理能力。
这项研究的三位作者均来自普林斯顿大学,论文主要有两大贡献:
其一,提出Grouped-Tied Attention(GTA),与已集成到LLaMA 3的注意力机制GQA质量相当,但KV缓存用量减少约50%。
其二,提出Grouped Latent Attention(GLA),与DeepSeek所使用的注意力机制MLA质量匹配,但解码速度更快,某些情况下比FlashMLA快2倍。
按照作者之一Ted Zadouri的总结:
GTA是GQA的有效替代品,而GLA是MLA的实用替代品。
一言以蔽之,通过优化注意力机制的内存使用和计算逻辑,在不牺牲模型生成质量的前提下,可显著提升大语言模型的推理效率和硬件资源利用率,尤其在长上下文场景中优势更为突出。
相关论文公布后,一众研究者也赶来祝贺~
那么,这项研究具体讲了些啥?
引入推理感知注意力机制
概括而言,论文核心引入了推理感知注意力机制,即针对模型推理阶段的内存冗余、计算低效、长上下文瓶颈等问题,重新设计注意力机制。
据Tri Dao介绍,这项研究的起点始于一个想法:
在推理驱动AI发展的时代,“理想”架构应该是什么样子?
尤其在涉及长上下文推理时,当前的大语言模型(LLM)面临内存访问瓶颈和并行性限制两大难题。
就是说,模型生成文字时,每次都要从内存里调取大量“历史记录”,不仅导致每个字生成变慢,而且只能按顺序生成、没法让多个芯片同时干活。
对此,团队打算从两个方向重新设计注意力机制:
更高的硬件效率:通过增加 “每字节内存加载的计算量”(算术强度),减少对内存带宽的依赖;
保持并行可扩展性:在不牺牲模型并行训练 / 推理能力的前提下优化解码速度。
而最终提出的GTA和GLA,在减少KV缓存用量的同时,模型质量保持与现有方案相当,且解码速度显著提升。
这里提到的“现有方案”,主要指早已闻名学术界的两种方法:
一是分组查询注意力(GQA)机制,它通过分组共享KV缓存减少内存占用,在视觉Transformer(ViT)等任务中表现良好,适用于大规模数据处理,目前已应用于Llama 3等开源模型。
二是多头潜在注意力(MLA)机制,最早可追溯到《Attention Is All You Need》这篇论文,后被DeepSeek再次带火。它关注的是在不同层之间如何融合注意力信息,能减少每一层的冗余计算。
不过,由于GQA仍需为每组查询头存储独立KV、MLA并行优化不足,故仍需进一步改进。
下面分别展开团队提出的新方法GTA和GLA。
分组绑定注意力机制GTA
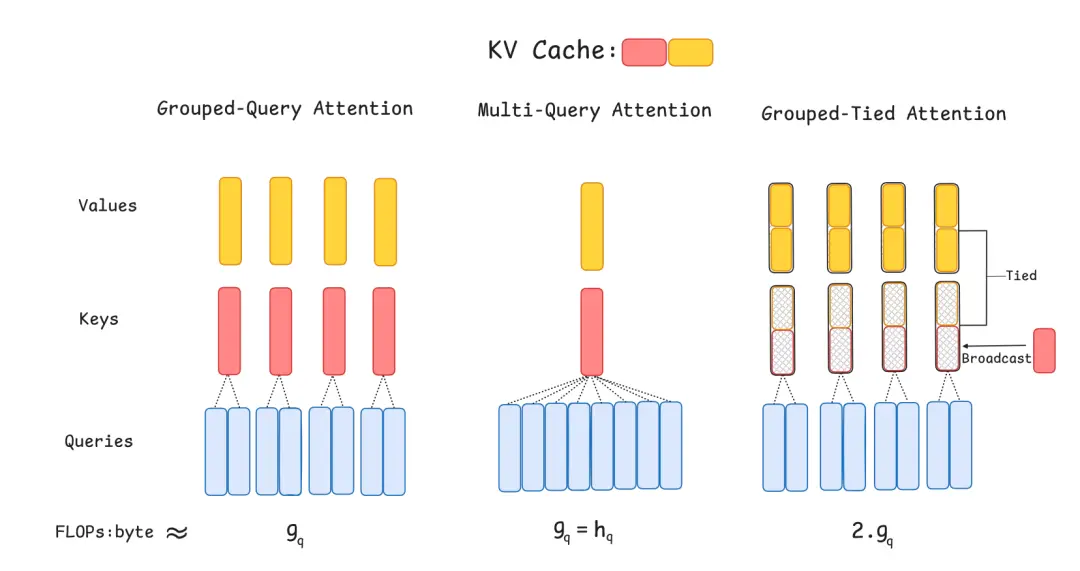
GTA的核心设计思路是:将不同查询头的键(Key)和值(Value)状态进行组合与重用,减少内存传输次数。
具体而言(右图),它将多头注意力的头分为若干组(Group),每组内的头共享相同的Key和Value参数。计算时,同一组内的头使用相同的KV缓存,仅查询(Query)参数独立。
相比之下,中间传统的多头注意力机制(MHA)每个查询头都有独立的键和值,由于没有共享,导致它需要更多的内存来存储所有的键和值。
再对比GQA来看(左图),GQA分组共享KV但每组仍独立存储,而GTA通过参数绑定实现了更彻底的KV重复利用。
分组潜在注意力机制GLA
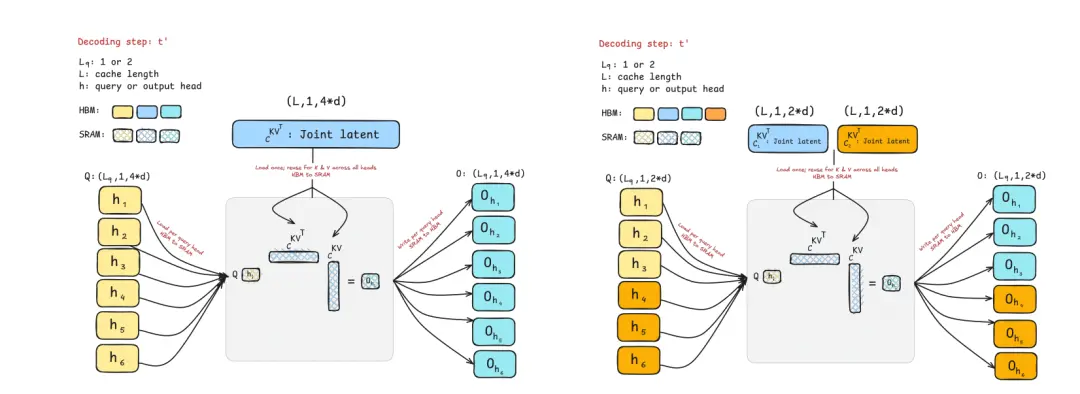
而GLA的设计则采用了双层结构:
潜在层(Latent Layer):引入固定数量的潜在Tokens,作为全局上下文的压缩表示,替代部分原始Token的KV缓存;
分组头机制:将查询头分组,每组头共享潜在Token的KV,同时保留与原始Token的交互。
在解码过程中,对比MLA(左图),GLA通过共享联合潜在表示减少了每个设备需要加载的KV缓存量,从而减少了内存访问量。
并且由于每个设备上的KV缓存量减少了,更多的请求也可以同时处理。
「GQA和MLA」的有效替代品
那么,GTA和GLA的效果究竟如何呢?
团队在四种规模的模型上进行了实验,包括小型(183M)、中型(433M)、大型(876M)和XL(1471M)。这些模型基于FineWeb-Edu-100B数据集训练,采用GPT-3架构和Llama 3分词器。
测试的指标主要分为两大类:
质量指标:困惑度(Perplexity)、下游任务准确率(Winogrande、SciQ等7个基准);
效率指标:每Token解码延迟、吞吐量、KV缓存占用量。
实验对比了GQA、MLA、FlashMLA、传统MHA等多种注意力机制。
困惑度实验显示,GTA在中大型模型上优于GQA,说明GTA可能更适合模型的进一步扩展;而GLA在多数场景下与MLA相当,说明GLA的设计是合理的,它能在并行计算和模型质量之间找到一个较好的平衡点。
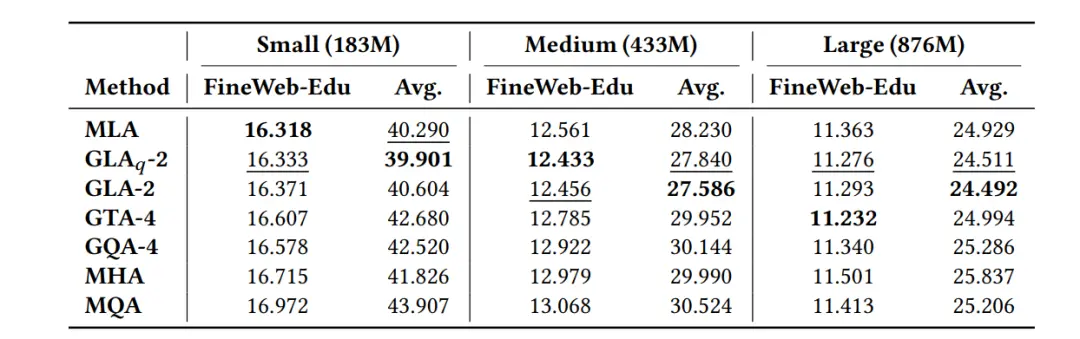
几种方案在下游任务中(涵盖典型常识推理、逻辑推理和知识问答等场景)的整体表现差距不大。
但从变化趋势来看(下图为从中型到大型),GTA和GLA可以保持或提高从中型到XL尺寸的下游任务性能。
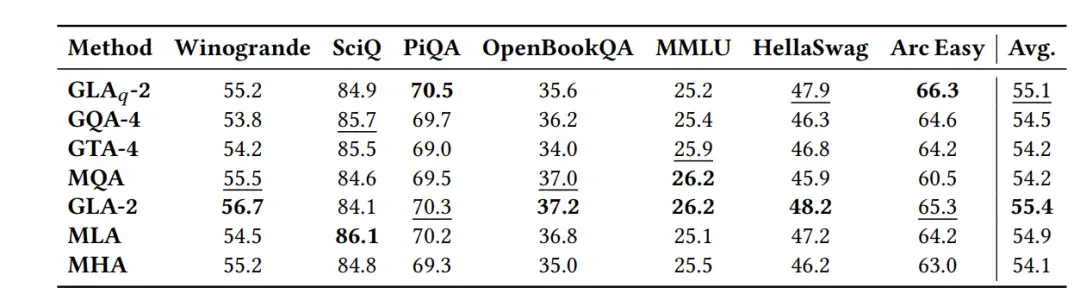
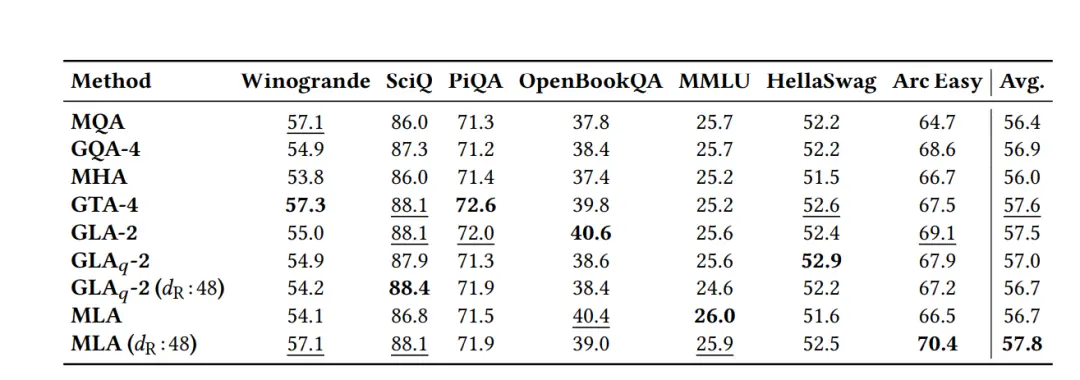
KV缓存方面,不牺牲模型质量的前提下,GTA相比GQA减少约50%的KV缓存,验证了 “参数绑定+分组重用” 的有效性。
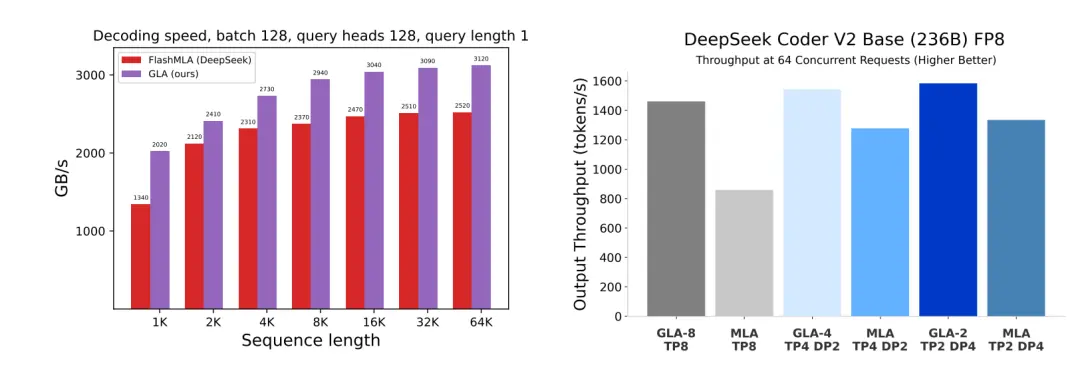
同时,针对查询长度为1的情况,MLA已接近计算瓶颈(达到610 TFLOPS/s ),而GLA尚未使计算资源饱和(360 TFLOPS/s )。
且随着序列长度从1K增加到64K ,GLA的解码速度比FlashMLA快2倍。
此外,在实时服务器性能测试中,对于64个并发请求的输出吞吐量(越高越好),相同并行方案下GLA的表现均优于MLA。
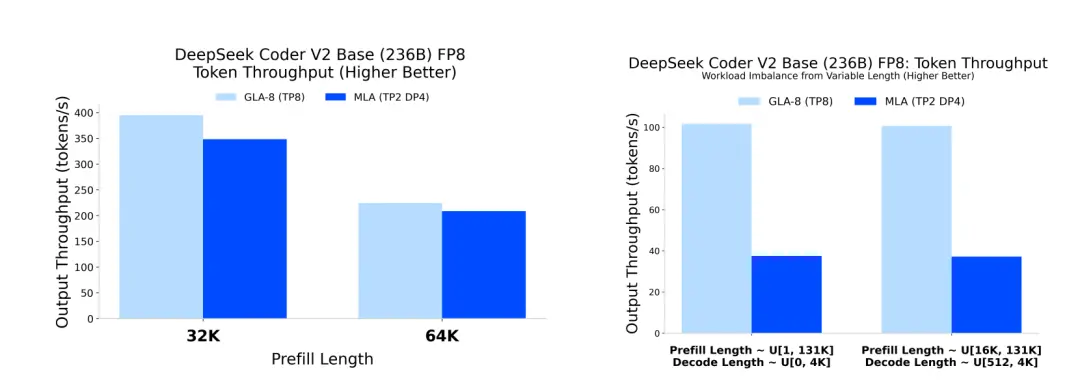
接下来,团队还在DeepSeek Coder V2 Base (236B)模型上,当使用FP8精度时,对比了二者在不同预填充长度和解码长度下的输出吞吐量。
结果显示,在预填充长度为32K和64K时,GLA-8的输出吞吐量明显高于MLA。这表明在处理长上下文时,GLA在吞吐量上优于MLA。
在处理不均衡负载时,GLA-8同样展现出更高的输出吞吐量。这表明GLA在处理不同长度的请求时,能够更有效地利用资源,提高整体性能。
以上实验均验证了论文作者的说法,「GTA和GLA」是「GQA和MLA」的有效替代品。
论文作者均来自普林斯顿大学
论文作者包括Tri Dao在内一共三位,均来自普林斯顿大学。

Ted Zadouri,目前是普林斯顿大学博士生,研究方向为机器学习。
之前曾在英特尔有过两段实习经历(研究深度学习),还短暂在AI创企Cohere担任研究员。

Hubert Strauss,普林斯顿大学研究工程师,研究方向为机器学习和模型深度学习。
本科毕业于法国知名工程学校Arts et Métiers,之后在佐治亚理工学院取得运筹学硕士学位。
毕业后曾有多段实习和工作经历,成为普林斯顿大学工程师之前曾在一家公司担任机器学习工程师,负责模型训练和Transformer优化。

Tri Dao,目前是普林斯顿大学计算机科学助理教授,还是生成式AI初创公司Together AI的首席科学家。
他因提出一系列优化Transformer模型注意力机制的工作而闻名学界。
其中最有影响力的,是其作为作者之一提出了Mamba架构,这一架构在语言、音频和基因组学等多种模态中都达到了SOTA性能。
尤其在语言建模方面,无论是预训练还是下游评估,Mamba-3B模型都优于同等规模的Transformer模型,并能与两倍于其规模的Transformer模型相媲美。
另外他还参与发表了FlashAttention1-3版本,FlashAttention被广泛用于加速Transformers,已经使注意力速度提高了4-8倍。

Anyway,回到这项研究,论文作者Ted Zadouri直言:
这只是迈向test-time推理“理想”架构的第一步!